
许多作者学习了多年统计分析,他们文章里的统计错误依然屡见不鲜。这些错误小则误导同行,大则直接被拒稿/撤稿。
埃米编辑给大家带来了eLife期刊(JCR生物学一区,国际影响力还不错的年轻期刊)的一篇文章,里面汇总了研究论文中最常见的10个统计错误,希望作者把握好设计实验、数据分析和撰写论文这三个重要环节,减少犯错概率,养成随时自检的习惯(篇幅所限,内容有删减)。
1 缺乏适当的控制条件/组
问题:一些额外因素可能会影响研究结果,例如练习效应或其他因时间流逝带来的改变。因此,对于这一类研究,应当将实验操作的效果与控制组比较。
控制组与实验组必须同时抽样,并进行随机分配,减少误差。研究者需要确保实验操纵对变量的影响大于时间对变量的影响(如果对变量进行前后测比较,应添加控制组)。
解决办法:如果实验设计不能将时间效应与干预效果区分开,那么关于干预效果的结论都是不可靠的。
2 分析差异却不直接比较
问题:人们经常认为干预的影响(干预前后或者两变量的相关性)指的是干预效应在实验组中显著,而在控制条件/组中不显著。基于此,研究人员有时会认为实验组中的效果大于控制组中的效果。这种推论很普遍,但却是错误的。
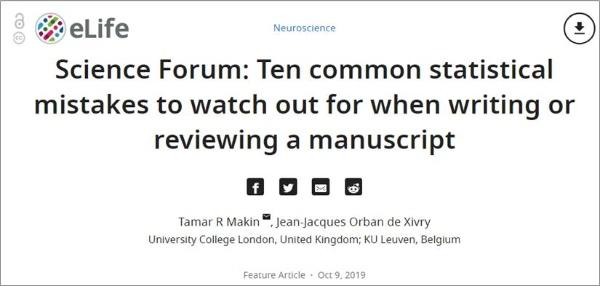
图1A:A组两个变量之间的相关系数显著(p<=0.05),B组与A组的相关性没有差别,但不显著。因此,不能推断一种相关更大。蒙特卡罗模拟可以用来比较两组之间的相关性。
图1B:类似的问题也会发生在评估干预效果时:在一组中干预效果显著,而在另一组不显著。实际上,这两组效果没有明显不同。这是由于单独运行了两次检验而没有放在统一的检验里同时比较造成的。
图1 两组效应比较
解决办法:任何时候想要比较效应的差异应该直接进行比较。两组相关性比较可以采用蒙特卡罗模拟。多组比较更适合ANOVA。非参数统计也提供了一些方法,但需要根据具体情况使用。
3 夸大分析单元
问题:实验单元是可以随机独立分配的最小观测值,即可以自由变化的独立数值。在经典统计学中,这个单元反映的是自由度(df)。不幸的是,研究人员往往混淆这些指标,导致理论和实践的问题。
有一个简单的前后测纵向设计,对10名参与者进行干预研究,其中研究人员用简单回归分析来评估主要测量指标与临床状况之间的相关性。
研究的分析单位应当是数据点的数量(每个参与者一个数据点,共10个),df为8。对于df=8,显著性的临界R值(α=0.05)为0.63。任何高于临界值的相关性都是显著的(p<=0.05)。
如果研究人员将参与者的前后测合起来,最终df=18,临界R值是0.44,就会更容易观察到统计上显著的影响。这是不正确的,因为将被试内和被试间的分析单元进行混合,导致了测量结果之间存在依赖:由于给定题目的前测得分不影响后测得分,也不会发生变化,这意味着只有8个独立的df。这最终导致在没有充足证据的情况下得出显著性结果。
解决办法:也许最合适的办法是使用混合线性模型。在这个模型中研究人员可以将被试间的变异定义为固定效应,被试间变异定义为随机效应。然而这个方法很容易被滥用,而且需要高级统计知识,因此在应用时需要更谨慎。
对于简单的回归分析,研究人员可以计算每个观测数据的相关性(前测,后测),并且基于现有的df解释R值。研究人员还可以对所有观测值进行平均,或者计算前测/后测的相关性并对所得R值进行平均。
4 伪相关
问题:参数相关的使用需要满足一系列假设,如果违反这些假设就会导致伪相关。
图2ABC: 两变量中的一个变量存在一个或多个异常值,就可能出现伪相关。远离其余部分的单个数值可能会使得相关数值增加。
图2DEF:伪相关也可能来自于集群。例如,当两个组的数据在两个变量上不同时,把数据汇集到一起分析就可能产生伪相关。
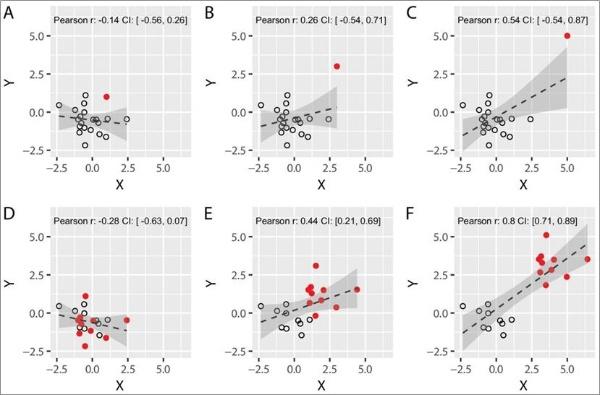
图2 异常值和集群对Pearson相关系数的影响
解决办法:选择稳健的相关分析方法(例如,bootstrapping, data winsorizing, skipped correlations),它们考虑了数据的结构,因此对异常值不太敏感。
5 样本量太小
问题:样本量较小时,人们可能会检测到较大的效应,对于真实效果的估计很不确定。样本量小也更容易遗漏数据中原本存在的效应(II型错误)。
另外,有限的样本往往无法严格检验正态假设。在回归分析中,偏离分布可能会产生极端异常值,导致虚假相关。
解决办法:来自小样本的单个效应大小或单个p值的价值是有限的,研究人员可以参考Button et al. (2013)是如何阐明这一点的。在样本量可能天然有限的情况下(例如,对罕见的临床人群或非人类灵长类动物的研究),应努力重复实验(无论是在案例内还是案例间),并进行可靠的控制(例如,确立置信区间)。评估案例研究已有一些统计解决方案(例如,Crawford t-test;Corbalis,2009)。
6 循环验证
问题:循环验证是指回溯选择某个数据的特征作为将要分析的因变量,从而导致统计检验的失真。循环验证的本质就是先根据数据特征选择因变量,然后再进行统计分析,被称为“双重浸渍”。
让我们考虑一项对神经元群体发放率的研究。当与总体数据比较时,实验操纵前后没有发现显著差异。
然而,研究人员观察到,一些神经元在操纵后增加发放率,而另一些神经元则在操纵后发放率减少。因此,他们根据基线观察到的活动水平将数据分成几个子组。这导致了显著的交互效应-那些最初发放率的神经元表现实验操纵后增加,而最初较高发放率的神经元在操纵后发放率减少。
这种显著的交互作用是人为扭曲选择标准和统计假象(可能只是回归到平均值,地板/天花板效应)组合的结果,这可以在纯噪声中观察到(Holmes,2009)。
解决办法:提前定义独立于数据的分析标准将避免循环验证。由于循环验证纳入了噪声来夸大期望效果,因此最直接的解决方案是使用不同的数据集(或数据集的不同部分)来指定分析参数(例如,选择子组)和检验预测(例如,检查子组之间的差异)。
7 p值黑客
问题:在数据分析中灵活使用不同方式可能增加获得显著p值的可能性(例如切换结果参数、添加协变量、不确定或不稳定的预处理程序、排除特殊异常值或参与者) 。
例如,当同一团队在整个论文中以不同的方式计算某一变量,却报告相同的结果时,或者当临床试验改变其结果时,数据分析的转换操作尤其明显。
也许最好方法是对边缘结果表现出一定的容忍度。如果实验设计、执行和分析良好,审稿人就不应该因为他们的数据而“惩罚”研究人员。
解决办法:研究人员在报告结果时应该是透明的,例如区分预先计划的分析和探索性分析,以及预测的结果和意想不到的结果。
8 没有进行多重比较矫正
问题:当研究者考察任务效应时,通常会检验多个任务条件对多个变量的影响。在任何涉及两个以上条件(或两组比较)的实验设计中,涉及的多个比较将增加检测到实际不存在的效应的概率 (假阳性,I类错误)。
例如,在2×3×3的实验设计中,即使没有效应,找到至少一个显著的主效应或交互效应的概率也是30%。
解决办法:研究人员应该公开所有测量的变量,并正确使用多重比较程序。
9 过度诠释非显著结果
问题:在结果不显著的情况下曲解统计检验结果是非常有问题的,也非常普遍。如果研究人员希望将一个不显著的结果解释为支持该假说的证据,则需要证明这一证据是有意义的,而P 值本身不足以达到此目的。
解决办法:重要的是报告效应大小和p 值。
在可能的情况下,研究人员应该考虑使用能够区分不充分证据和支持无效假设的证据的统计方法(例如,贝叶斯统计或等价性检验)。
除非已经预先确定他们是否有足够的统计检验力来识别期望效应,或效应的置信区间是否包含零。否则,研究人员不应该过度解释非显著结果。
10 错把相关当因果
问题:这可能是解释统计结果时犯的最古老、最常见的错误。当发现两个变量显著相关时,通常很容易认为是一个导致了另一个,这是不正确的。
观察到不同国家的年巧克力消费量与诺贝尔奖获得者数量之间的显著相关性(r(20)=0.79;p<0.001),导致了(不正确的)建议,即巧克力摄入量为诺贝尔奖获得者提供了营养基础。
解决办法:如果可能,研究人员应该尝试探索与其他变量的关系,为解释提供进一步支持。例如,使用分层建模或中介分析(有足够的统计检验力)。否则,当证据相互关联时,应避免使用因果推断。
扫描下方二维码,关注【埃米编辑】微信公众号,获取更多SCI论文写作资料。

编译/婷婷
具体文章信息详见原文链接:https://elifesciences.org/articles/48175



